
AUDL Data Generation
A quick explanation of the process taken to obtain AUDL data specific to year by year player statistics
Introduction
The AUDL is a professional ultimate frisbee league that started in 2010. This means the league, and more specifically, the professional level of the sport has only been around for about 13 years. Most sports, it seems, see the most rapid growth and quickest evolvement of gameplay and performance in the years closer to their inception. I want to explore if this is the case with professional ultimate frisbee, specifically in the AUDL. General questions such as, “Has the game gotten cleaner?” or “Are players more skilled?” can be answered as we dig through specific statistics like turnovers, completion percentage, and throwing yards available through the AUDL API. As we explore the season by season player performance data, we hopefully will be able to get a general idea of how player performance has evolved over the last 13 years of league play.
Data Generation
Data was obtained through the AUDLs official API located at https://www.backend.audlstats.com/api/v1 (Official documentation is found at https://www.docs.audlstats.com/). I first needed to obtain a list of players for every year of interest. For the purpose of this project I only go back to 2015. The diagram below outlines the process I took to get the final dataframe:
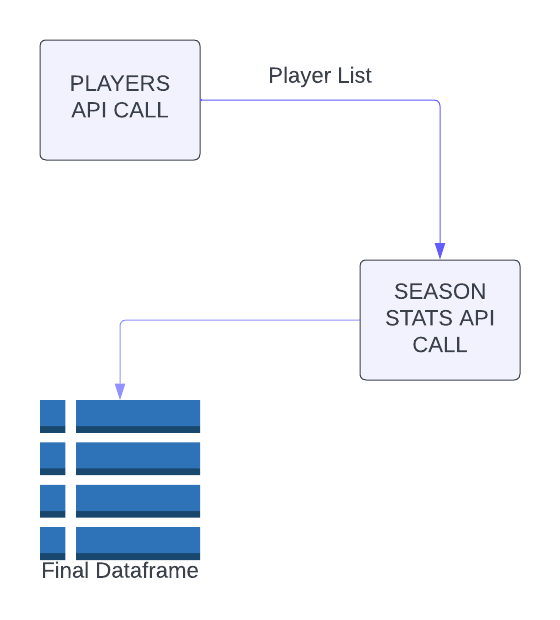
As you can see it is a fairly simple process. I first obtain a list of players from the Players API call, and then pass that list into the seasonal player stats API call and then transform that data to get the final data frame.
Below is a chunk of the code used to obtain the player list:
base_url = "https://www.backend.audlstats.com/api/v1/"
## Get A List of Players ##
# Players Endpoint
players_endpoint = base_url + "players"
# get years 2015-2023
params = {'years': ['2015,2016,2017,2018,2019,2020,2021,2022,2023']}
r = requests.get(players_endpoint, params=params)
players = r.json()
players_data = players['data'] # Access the 'data' key from the JSON response
players_list = []
for player in players_data:
player_info = {
'id': player['playerID'],
'firstName': player['firstName'],
'lastName': player['lastName'],
'year': player['teams'][0]['year'] if player['teams'] else None # Accessing the 'year' within 'teams' list
}
players_list.append(player_info)
players_df = pd.DataFrame(players_list)
As you can see I passed in the years of interest as a parameter to the API call, specifically the players endpoint. This endpoint returned a list of players with their id, first and last name and the team they played for that year. Since I am only interested in getting player stats not related to teams, I save the names and the year associated with that name.
With this dataframe of names, I used the player stats endpoint to then get the stats for each player for each year they played (going back to 2015). Below is a chunk of the code:
# Player Stats Endpoint
stats_endpoint = base_url + 'playerStats'
# Loop through list of players in groups of 100
batch_size = 100
num_batches = math.ceil(len(player_ids)/100)
# Initialize stats_df
stats_df = pd.DataFrame()
for i in range(num_batches):
start_index = i * batch_size
end_index = (i + 1) * batch_size
batch_ids = player_ids[start_index:end_index]
# Make API call with the batch of player IDs
params = {'playerIDs': ','.join(map(str, batch_ids))}
r = requests.get(stats_endpoint, params=params)
stats = r.json()
stats_data = stats['data']
names = [{'firstName': player['player']['firstName'], 'lastName': player['player']['lastName']}
for player in stats_data]
# Create a DataFrame for the batch of stats
batch_df = pd.DataFrame(stats_data)
# Create a DataFrame for names and merge with batch_df
names_df = pd.DataFrame(names)
batch_df = pd.concat([batch_df, names_df], axis=1)
# Append to final df
stats_df = stats_df.append(batch_df, ignore_index = True)
The general process taken is (1) passing in a list of 100 player names (the API call limits you to 100 players per call), (2) extracting the relevant data from the returned json data. It took a little creativity, but with this process I was able to obtain a dataframe that contained the name of the player, the year, and a number of their overall season statistics.
Ethical Considerations
Since I was using a free API, there weren’t many ethical considerations to make when actually obtaining the data. I would consider not over using the API as the league is relativley small and may not have the resources to handle a constant tapping of the API, but the scope of this project just entails a one-time usage of the API and so I wasn’t concerned with over-using it.
Conclusion
From this blog post you can see the steps taken to obtain season by season player statistics from the AUDL API. It included using requests library in python and multiple API calls from different endpoints to get the cleaned data. To see the full script used for data generation or look at the data yourself, see my github repository at https://github.com/22ermiller/audl_stat_comp/ (Data generation file: data_generation.py, Data: player_season_stats.csv).